Mục đích chính của vệt bài này là cung cấp các hiểu biết “chả có gì mới” về các cấu trúc dữ liệu cơ bản (bao gồm các danh sách, hàng đợi, ngăn xếp, cây, bảng băm và đồ thị) bằng cách viết giản lược và những ví dụ minh họa. Để hiểu được các bài viết trong vệt bài này, bạn cần có kiến thức cơ bản về ngôn ngữ lập trình (Java, C, C#) trước. Tôi sẽ dùng Java làm ngôn ngữ minh họa, nhưng các vấn đề được đề cập thì cố gắng trừu tượng hóa nhất có thể, vì CTDL là một vấn đề nền tảng, không phụ thuộc ngôn ngữ – một vấn đề mà mọi lập trình viên đều phải quan tâm không kể là chị ta đang sử dụng ngôn ngữ nào. Và tôi sẽ cố gắng dùng ngôn ngữ “bình dân’, thay vì ngôn ngữ “học thuật” như các sách về CTDL hay dùng.
Chúng ta cùng bắt đầu với một câu chuyện thường gặp trong các tình huống lập trình. Giả sử bạn nhận được một class được viết bởi người khác (từ một API nào đó, hoặc từ một thành viên khác trong team) với một hàm quan trọng getData() có nguyên mẫu như sau:
public List<Integer> getData();
Hàm này trả về tất cả các dữ liệu quan trọng cho các chức năng mà bạn sẽ code ngay sau đó. Dữ liệu trả về là một danh sách (List), và bạn bắt đầu viết đoạn code đầu tiên để duyệt (traverse) toàn bộ dữ liệu trong đó như sau:
//duyet danh sach
for (int i = 0; i < aList.size(); i++) {
System.out.println(aList.get(i));
}Đơn giản, đúng không? Có bao giờ bạn đặt câu hỏi “đoạn code trên có vấn đề gì không”? Nếu chưa, thì bạn vừa được đặt câu hỏi rồi đấy. Có vấn đề gì không?
Đoạn code đó về bản chất là “không vấn đề gì” nếu nó không rơi vào trường hợp oái oăm như sau: cái Collection mà người viết hàm getData() đã dùng để tổ chức dữ liệu là LinkedList. Khi đó, việc dùng không đúng cách như trên có thể dẫn đến hậu quả rất tồi tệ: bạn phải ngồi chờ hàng tiếng đồng hồ để chờ chương trình kết thúc, trong khi nếu biết cách dùng cho đúng, bạn chỉ mất vài phút để duyệt hết một danh sách một triệu phần tử (thường thi khi bạn code, bạn chỉ chạy thử với vài chục phần tử nên có thể không phát hiện ra, nhưng một chương trình chạy thì vài chục nghìn cho tới một vài triệu bản ghi nằm trong một collection là chuyện … thường ngày ở huyện), như trong hình ghi lại từ Profiler (nếu bạn chưa dùng Profiler, hãy xem qua bài “Dùng Profiler đo hiệu năng ứng dụng Java“) như sau:
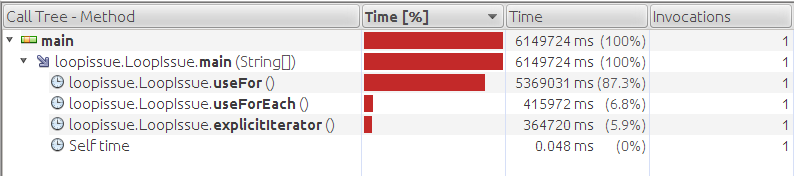
Ảnh: List performance
Hàm useFor() với đoạn code ở trên cần tới 5369031 ms (gần 90 phút) để hoàn tất việc duyệt qua tập hợp dữ liệu. Thử tưởng tượng nếu bạn code một ứng dụng web e-commerce, khách hàng sẽ bỏ bạn vì không thể kiên nhẫn đến thế. Nhìn vào hình trên, bạn thấy hàm useForEach() có thể thực hiện công việc tương tự mà chỉ cần tới 415972 ms ( chưa tới 7 phút), đây là lõi của hàm useForEach():
//duyet qua danh sach
for (Integer i : aList) {
System.out.println(i);
}Sự khác nhau giữa hai đoạn code chỉ ở một điểm mấu chốt: lựa chọn for hay for-each để duyệt aList(). Đến đây bạn có thể đặt câu hỏi: vậy cái hàm useFor() chạy như rùa kia sai ở chỗ nào?
Câu trả lời rất đơn giản: việc duyệt theo kiểu random access (ngẫu nhiên) như trong useFor() (gọi hàm get(i) để duyệt phần tử thứ i) là sai nguyên tắc. Vì LinkedList được tổ chức đặc biệt, nên chỉ có thể được truy xuất tuần tự chứ không phải là truy xuất ngẫu nhiên thông qua chỉ số như là một danh sách dạng mảng. Để truy xuất phần tử thứ i của một danh sách liên kết, bạn sẽ phải bắt đầu từ phần tử đầu tiên (head), tuần tự đi qua các phần tử kế tiếp (thứ hai, thứ ba, v.v.) cho tới khi đến phần tử thứ i. Do đó, mỗi lần viếng thăm phần tử i, bạn tiêu tốn đúng “i” lần bước, do vậy bạn “đi” rất chậm, đặc biệt là khi “i” lớn.
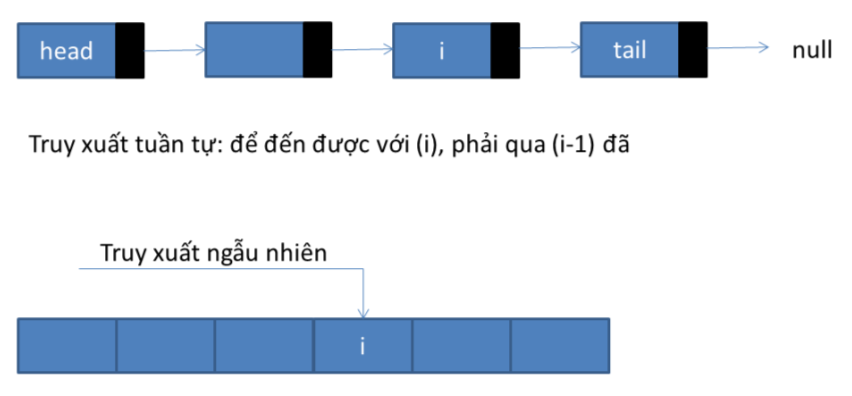
Với việc dùng for-each, danh sách sẽ được dùng theo cách tối ưu với danh sách liên kết. Để hiểu rõ cơ chế duyệt theo for-each, chúng ta thử nhìn một đoạn code minh họa khác như dưới đây:
for (Iterator<Integer> it = aList.iterator(); it.hasNext();) {
System.out.println(it.next());
}Trong Java, mỗi một tập hợp (collection) đều được tổ chức với một iterator (một đối tượng phụ trợ cho việc duyệt qua các phần tử bên trong tập hợp). Khi duyệt qua aList, iterator của một LinkedList đã đánh dấu phần tử đang duyệt (current), như đang đặt con trỏ (cursor) ở đó vậy; đo đó, khi gọi hàm it.next(), thì iterator đó không phải mất công dò từ đầu (head) cho tới phần tử thứ i, mà chỉ cần lần theo liên kết để đến với phần tử tiếp theo, tính từ vị trí đang đứng (current), mất thêm đúng một lần di chuyển. Đó chính là lí do tại sao hàm useFor() lại mất thì giờ đến vậy, trong khi hàm useForEach() và explicitIterator() thì lại rất tiết kiệm thì giờ.
Bạn thấy đấy, chỉ khác có mỗi cái lệnh lặp mà chuyện xem ra phức tạp. “Sai một li đi một dặm”. Trong lập trình, đôi khi tốc độ của chương trình chỉ do một dòng code quyết định. Và vệt bài “Tìm hiểu Cấu trúc dữ liệu” sẽ cố gắng cung cấp các hiểu biết cơ bản để bạn không phải mất “dặm” nào, với các tình huống liên quan đến cấu trúc dữ liệu. Nhưng đây là câu chuyện dài kì, hãy tạm dừng ở đây đã. Ở bài tới (sẽ rất sớm thôi) chúng ta sẽ trò chuyện về các cấu trúc tuần tự: danh sách.
Phụ lục: dưới đây là code trong bài để bạn chạy thử, hãy cho BOUNDARY nhận các giá trị khác nhau và quan sát kĩ hơn về performance đo được bởi Profiler.
/**
*
* @author neotan
*/
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class LoopIssue {
public static final int BOUNDARY = 1000000;
public static void main(String[] args) {
List<Integer> aList = (new LoopIssue()).getData();
useFor(aList);
explicitIterator(aList);
useForEach(aList);
}
/**
* Get data from a datasourse, a simulation of real situations
*/
public List<Integer> getData() {
List<Integer> aList = new LinkedList();
for (int i = 0; i < BOUNDARY; i++) {
aList.add(i);
}
return aList;
}
static void useFor(List<Integer> aList) {
//read the list
for (int i = 0; i < aList.size(); i++) {
System.out.println(aList.get(i));
}
}
static void useForEach(List<Integer> aList) {
//read the list
for (Integer i : aList) {
System.out.println(i);
}
}
static void explicitIterator(List<Integer> aList) {
//read the list
for (Iterator<Integer> it = aList.iterator(); it.hasNext();) {
System.out.println(it.next());
}
}
}Theo Tạp chí Lập trình
